
Find it to Mind it
Taxonomies as Gap-Finders


Knowledge can be, like, hard to know itself and stuff.
∼ incorrectly attributed to Shakespeare
A fascinating book that almost no one ever finishes, Gödel, Escher, Bach (guilty!), plants a seed early about self-reference and incompleteness that has stuck with me. In essence: you cannot ever have a set that captures everything. The largest possible set still cannot contain itself.
Knowledge can only and always be imperfect and incomplete.
The less elegant but more practical impact of this reality: we can often be blind to key aspects of the information we are working with. These understandings can sit at an intuitive layer. They “make sense” so we don’t examine them. This treatment of information works fine, until it doesn’t.
So an important part of minding the gaps in information, so you don’t step into one, is finding the gaps.
One effective way we as content strategists, technical writers, and just information artists in general can find these gaps is to map out the categories of what we think we know. A great tool for this is taxonomy.
Taxono-what?
To avoid irony from the start, it’s good to clarify what we mean by taxonomy.
Taxonomy came into being as the science of naming, describing, and classifying living things. It has since been extended into information science, where it does similar work on ideas, documents, and data.
For us as information artisans, a taxonomy is a hierarchical system of classification that organizes information into categories and subcategories for our specific purposes.
This can help us in many ways. There is an infinite number of ways to organize information, in addition to not organizing at all. There are a finite number of ways to organize it usefully for specific tasks.
As Gödel’s theorem (very existentially useful even for non-mathematicians like many writers) suggests, it is useful to keep in mind that perfection is elegantly impossible. There is no perfect way to organize sets that cover everything.
Requiring a hierarchy is perhaps the most useful part of this. It enforces a division of information into more important and less important information, from the very start. You have to prioritize by definition.
This points toward a further practical aspect to keep in mind: what you deliberately don’t capture can be as important as what you do. In fact, excluding what isn’t needed for capturing is the worthy part of the same process.
OK, so how do we taxonomize (tm)?
One of the non-intuitive difficulties in creating a taxonomy is: where to start?
The ways to categorize systems are effectively infinite. Even accounting for the principle that you can’t make a set of all sets, the possibilities are still infinity minus one.
The flip side is that with this level of openness, almost any approach will be productive. Even if you end up with something quite far from what you started with, the most important thing is ending with a taxonomy that gives you what you need. Often by surfacing your gaps in the process.
Process in practice: my open source project Code-wiki (aka Docsy McDocsface)
Since I launched into vibe coding, both for personal interests and professionally, my GitHub repos have multiplied greatly. When they reached 30, including both public and private repos in various stages of development and release, I started feeling familiar pain from a new direction. I realized I was experiencing a lack of documentation from the developer and project manager side.
There also did not seem to be any app set up for my specific use case, including reading from and writing to both public and private repos. So I went full meta and vibe-code created Code-wiki, to help me document and keep track of all my other vibe-code projects. I made it proudly open source, which it still is, as a way to help others who might come across the same difficulties.
This helped resolve my difficulties for about a month.
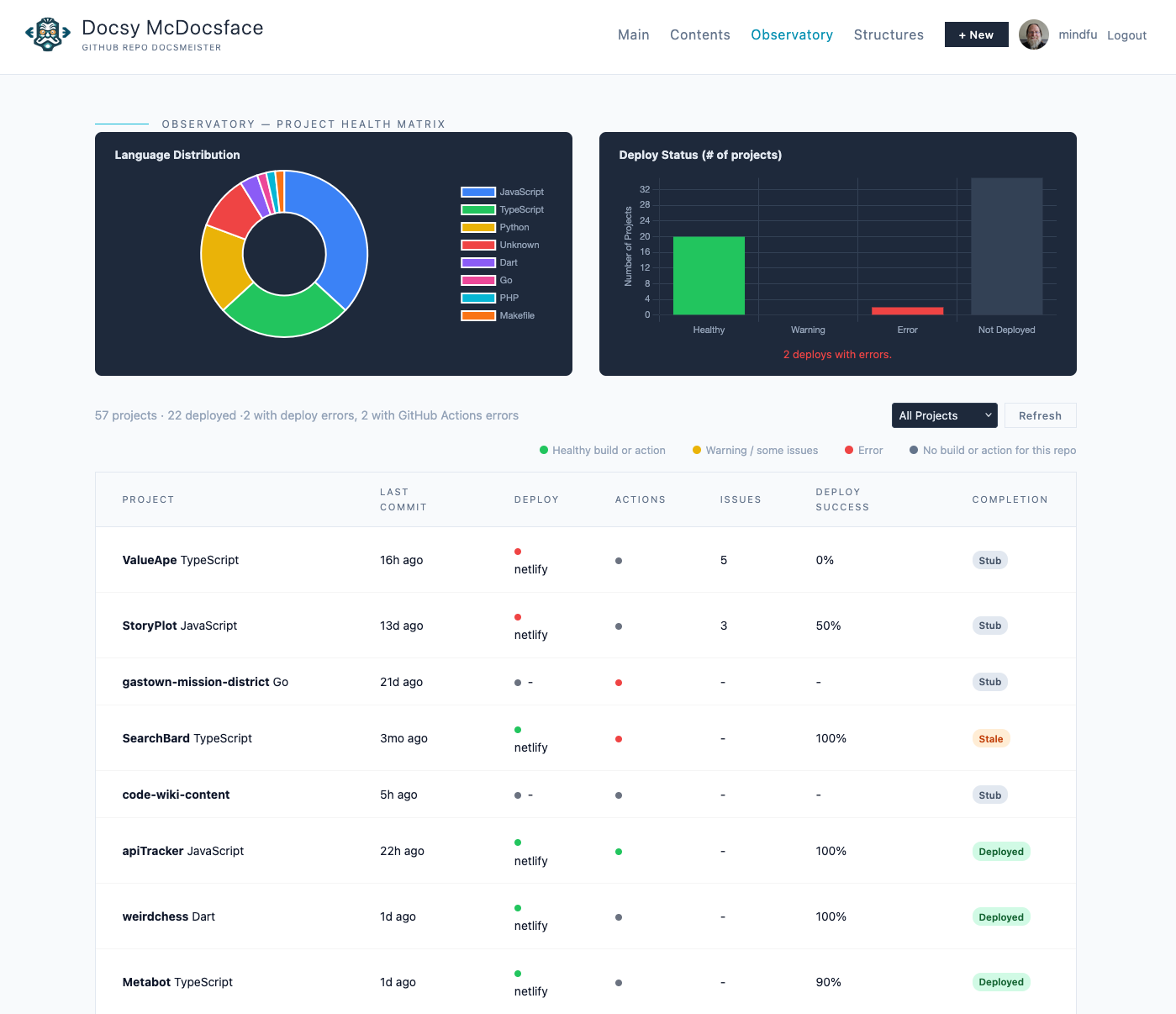
When my app repo count reached over 50, new information complexities and needs emerged. What stages of release were most of my apps at? How many would never need to be further developed, including those that were superseded? Which methods and resources were ending up the most useful, and what languages and packages were showing up as easiest to implement?
Besides these questions taking up more time per project, they were also taking up paid token usage. My AIs were reading entire code bases, or even concentrated README.md files or threads, to answer these questions as needed on a per-project basis. Reinventing wheels.
I realized a taxonomy could help solve all of this. I could define all I currently needed to know about my apps, add in room for what could be of future use, and then use AI once across to apply that taxonomy to my entire set of public and private repos.
Once that was done, all my repos would be much easier for me and any agent to search. Cheaper in tokens, and cheaper in the willpower and focus I expend. It would also make it easier to create MCPs for further coding.
So now it was time to start.
Pass 1: From feels to surface reals
The way I like to start with creating a taxonomy, like many ways of thinking about things, is to a certain degree intentionally aesthetic. What feels most important? This is the top of the hierarchy. Then what feels next important, for each of those top items?
Once that is done, what known categories remain, and what highest-level and next-highest level categories do they belong to?
Once that is on paper, I can investigate it and find out what is actually most important. What is central, what is secondary, tertiary and further. How the map I’m drafting actually fits the territory.
The most important thing in this stage is to treat categories as solid for now, while also entirely disposable at a moment’s notice. To paraphrase the informal knowledge workers 38 Special, “hold on loosely,” but in this case do let it go.
An outline is fine for this. For once, even longhand is useful. Drawing it out on paper, wasting a couple of sheets if needed. Adding to it until it captures all the detail, even what seems like it might not be needed but is a clear and definable aspect. Then applying what’s useful. Then seeing what can be simplified in the remainder.
These can be very useful to apply as questions, for the specific task. Applying this to Docsy McDocsface, and its intent to help me and my agents keep track of my repos, the questions that felt most important were:
• What code is the app in each repo made with?
• What resources does the app use when running?
• Is the app staged or standalone, or something else?
• What is the app’s current state of development?
• Is the repo it’s sitting in private, or public?
Pass 2: Answers and further questions
Answering those questions for specific applications, such as my app Weird Chess, I came up with some specific answers. It uses Flutter, and also has API calls to an AI for responding to players’ chess moves and providing commentary. It’s standalone on the iOS App Store, but also staged on Netlify if I want to test it. It’s currently feature complete, with further updates along the line. Its repo is private.
Pass 3: Informal sorting into my favorite three buckets
Now that I have those answers, what categories do the answers sort into?
Perhaps due to my writing habit, it helps to sort the candidate categories into three buckets:
• Nouns. What is factual and unchanging about the thing? These become your stable classifiers.
• Verbs. What actions, relationships, or states apply? These change over time. Separate them from the nouns.
• Adjectives and adverbs. Modifiers for the nouns and verbs. Notes, qualifications, commentary, observability. This is also a good de facto extension area for future taxonomy needs.
That split alone can perform most of the work. The “does this belong here or there” debates can dissolve once the function of each answer emerges. It’s typically and clearly either a thing, an action, or an aspect of a thing or an action.
Once these were done, a quick step off of this path to see what others might have done.
Pass 4: A detour through SKOS
At this point it can also be useful to work from a wheel that exists, rather than completely reinventing my own. Fortunately information science has a whole space full of wheels I can borrow from.
SKOS, the Simple Knowledge Organization System, is a W3C standard that emerged from library and information science to describe exactly this kind of structure: concepts, the notes that describe them, and the relationships between them. It gives you a shared, argued-over set of ideas like definition, scopeNote (how a term should be used), editorialNote (for maintainers), historyNote (how a concept has evolved), and changeNote (specific edits), plus relationships like broader, narrower, and related.
SKOS has been quietly doing this work for about twenty years. Most developers never encounter it. A lot of technical writers haven’t either.
The other option to consider is that any other wheel is likely not perfectly suited to your purposes. A bike tire and a truck tire are both descended from the same general idea, but you would not use one in place of the other.
Here is where another creative part of information work arises: determining what to borrow completely, what to shape, and what to create. For this specific example, SKOS doesn’t currently have terms for software development concepts like “software module” or “deployment state”. But it knows what a scopeNote is, and it has been arguing with itself about that definition for two decades. I’m happy to benefit from some results of that debate by using the results.
Three concrete wins for the effectiveness of a SKOS-aligned taxonomy:
1. Semantic precision without bikeshedding. “Bikeshedding,” a phrase from near 70 years ago, refers to scientists’ getting lost in a debate about the proper color of a nuclear reactor’s staff bike shed, instead of decisions about the nuclear reactor.
You can benefit from these potentially endless nitpicking decisions having already been moved past. You don’t have to deliberate on whether a note belongs in “notes” or “comments” or “description.” SKOS has already drawn those distinctions for you.
2. Interoperability, present and future. If you ever pipe the taxonomy into a SKOS-aware tool, a thesaurus browser, a concept-scheme visualizer, or a graph database that speaks RDF, the SKOS-aligned parts port cleanly. The custom parts are yours to translate.
3. Extensibility with a known shape. SKOS is designed to be extended. Adding a new note type or relationship that follows SKOS conventions keeps the whole system coherent. Ad-hoc fields tend to fragment over time.
That third point is itself a useful strategy in minding a gap. When an information system might seem stiff and easily broken by information that doesn’t fit, that’s because the shape doesn’t fit the field. The field is right. Update the shape.
Pass 5: The rubber wheel meets the road
Reviewing these results brought me a couple of surprises. The first surprise was that initially exploring what felt most important, I started with two main categories:
What the app in the repo was made of, as the nouns.
What state the app was in, as the verbs.
Other aspects like the repo’s public or private nature, the languages and resources for the app etc., were adjectives and adverbs for these two categories.
What emerged that I did not expect was that there were actually two kinds of state to track:
The app’s current place in the development lifecycle
Its place in curation
That wasn’t something I had articulated before I sat down to do this. It was a genuine unknown unknown, and it shifted the design.
The second surprise was realizing I had potentially two different documentation output needs, while still having only one internal development need. I wanted the documentation publishing side to respect the difference between public and private repos, so users who weren’t given access to private repos wouldn’t see them. But I wanted the internal use and development side, me and my local AI agent collaborators, to easily access the taxonomic information for all the repos.
That distinction would not have surfaced from looking at the repos. It only surfaced by trying to describe them. Which is the final point: these are the benefits of understanding that come from applying a taxonomy.
The final-for-now product
As a lot of good technical writing does, the exercise of creating a useful taxonomy forced clarity that led back into improving the product. It specifically resulted in me adding new observation functionality to Docsy McDocsface, to distinguish life cycle from launch state.
The result was a far simpler taxonomy than expected. A few extra fields sorted into a stable shape. Key decisions were made around the taxonomy schema, which included six facets (for example, type, stack, platform) and two state fields (lifecycle, curationState).
Below is the template. Notice how the three-part meta-framework maps onto it. The nouns (FACETS) sit on the left. The verbs (STATE FIELDS and RELATIONSHIPS) sit in the middle. The adjectives (NOTES, CHANNELS, VALIDATOR) sit on the right. NOTES are wholesale SKOS. RELATIONSHIPS are partly SKOS (broader, related) and partly my own domain additions (usesModule, dependsOn, appliesTo, supersedes).
This hybrid is the canonical SKOS extension pattern: keep the standard associative relationships. Then where the standard does not cover your domain, add your own.
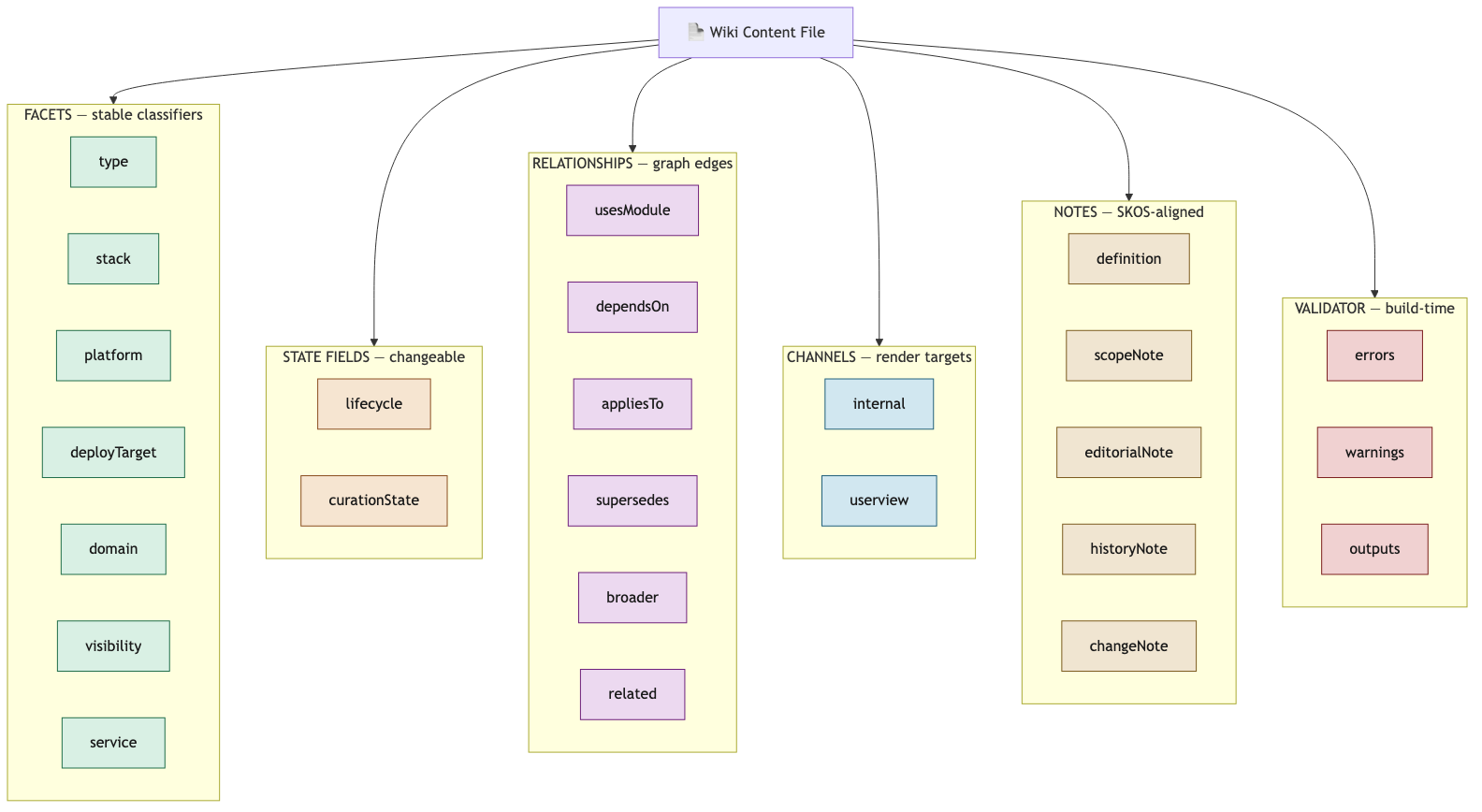
Figure 1. Wiki Content File taxonomy template, showing facets, state fields, relationships, channels, SKOS-aligned notes, and validator sections.
Here is the same shape as applied to my already shipped app, Weird Chess. This is what a filled-in taxonomy file looks like in practice.
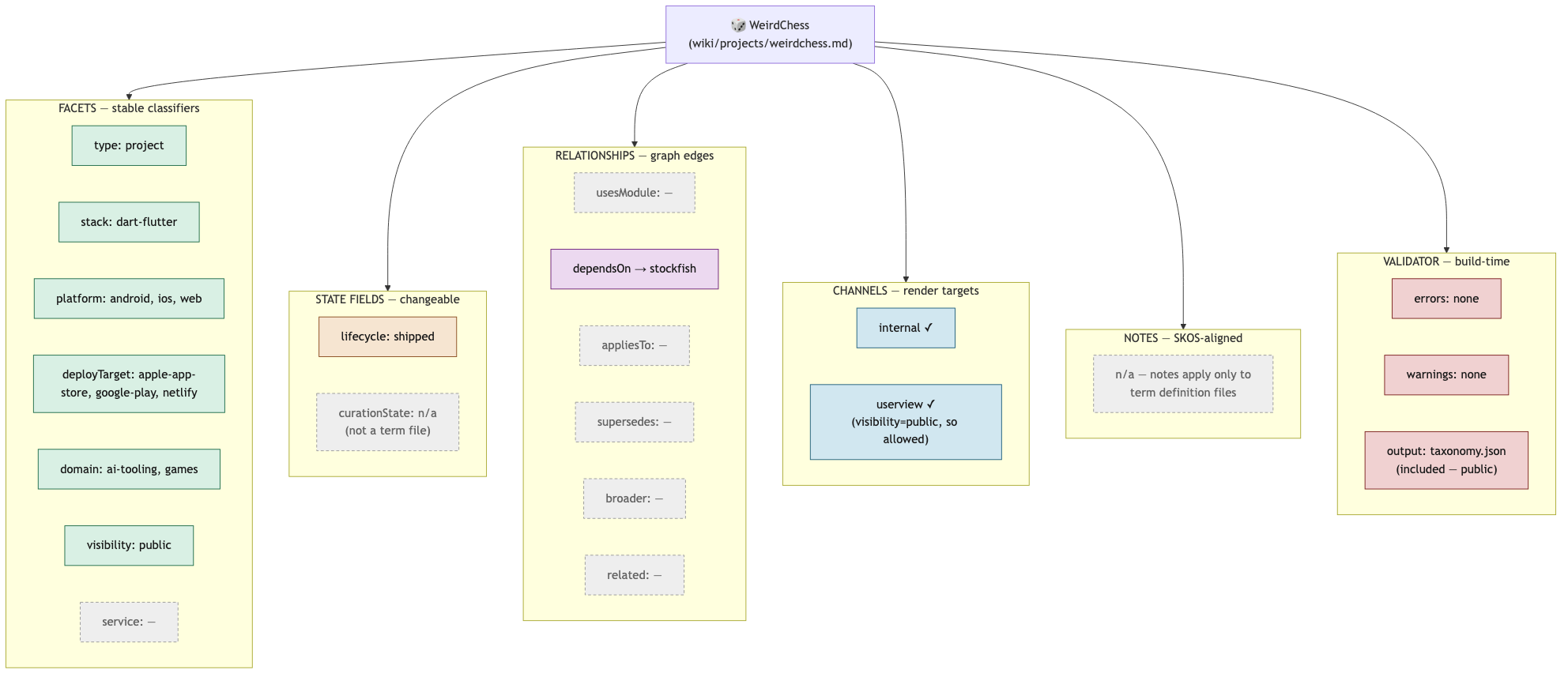
Figure 2. WeirdChess taxonomy instance, showing concrete values filled into each section of the template.
This helps me understand this project in particular. It also helps my local AI agents understand it, and more quickly, without searching entire code bases when I work with them collaboratively to add new features, fix bugs, or repurpose the apps’ modular code for entirely different apps.
Conclusion
Taxonomies are great ways to make some of the unspoken known. Resolving the differences between categories can also surface unknown unknowns.
Constructing one usually results in two things. The bonus is the useful taxonomy itself. The active benefit is the investigation and discoveries that come from resolving the conflicts and uncertainties the taxonomy uncovers on the way in.
That’s the gap worth minding. Not just the one between what you know and what you don’t, but the one between what you already know and what you have not yet made explicit.
This post is part of Per the docs, a monthly collaborative series where technical writers explore different aspects of our craft. Each month features a new topic with perspectives from writers across the community.
Read more perspectives from the April 2026 topic Mind the Gap here.
← Previous post:
Content Gap Analysis by Brandi Hopkins
→ Next post: Unwritten rules that experienced writers follow instinctively by Jill Shaheen
See the full list of participants and articles here.